
Zgodnie z artykułem 32 RODO, administrator i podmiot przetwarzający dane osobowe wdrażają odpowiednie środki techniczne i organizacyjne, aby zapewnić stopień bezpieczeństwa odpowiadający występującemu ryzyku, w tym między innymi pseudonimizację i szyfrowanie danych osobowych.
Technikami, które pozwalają na utrzymywanie korzyści z posiadania danych oraz minimalizują ryzyko w związku z utratą prywatności, jest anonimizacja lub pseudonimizacja. Mimo wykorzystania zaawansowanych algorytmów, stworzenie prawdziwie anonimowego zbioru danych przy jednoczesnym zachowaniu użyteczności informacji, nie jest prostą operacją. Istnieje ryzyko, że zbiór danych uznany za anonimowy może być połączony z innym zbiorem danych w taki sposób, że możliwe będzie zidentyfikowanie jednej lub więcej osób.
Wyróżnia się dwie główne techniki depersonalizacji danych osobowych. Jest to anonimizacja oraz pseudonimizacja. Największa różnica między nimi polega na tym, że pseudonimizacja jest procesem odwracalnym, a anonimizacja już nie.
Rysunek 1. Techniki depersonalizacji danych

Źródło: Opracowanie własne.
Pseudonimizacja jest to odwracalny proces, polegający na zastąpieniu danej rzeczywistej nazwą przybraną, czyli nadanie jej tak zwanego pseudonimu. Pseudonimizacja utrudnia identyfikację, natomiast umożliwia przypisanie różnych czynności tej samej osobie (bez znajomości jej danych osobowych) oraz łączenie rożnych zbiorów danych między sobą. Pseudonimizacja skutecznie podwyższa bezpieczeństwo przetwarzania danych, ale nie jest równoznaczna anonimizacji w związku z czym, dane poddane pseudonimizacji dalej podlegają pełnej ochronie.
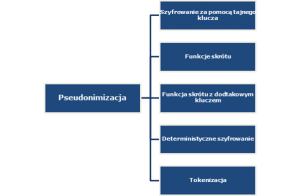
Poniższy rysunek prezentuje podział pseudonimizacji na pięć głównych kategorii.
Rysunek 2. Podział technik pseudonimizacji
Źródło: Opracowanie własne.
Najczęściej stosowanymi technikami pseudonimizacji są:
- Szyfrowanie za pomocą tajnego klucza – dane osobowe są nadal przechowywane w zbiorze danych, ale w formie zaszyfrowanej. Posiadanie klucza szyfrującego pozwala na pełen dostęp do danych osobowych. Używając szyfrowania, które zachowuje aktualne standardy bezpieczeństwa, możliwość odszyfrowania danych jest możliwa, ale tylko z użyciem klucza szyfrującego.
- Funkcje skrótu – polega na skróceniu dowolnego ciągu znaków do wyrażenia o stałej, określonej długości (dowolnej informacji przydzielany jest unikalny identyfikator). Funkcji tej nie można odwrócić, tak jak w przypadku szyfrowania. Jakkolwiek, znając zakres wartości, jakie zostały poddane skracaniu oraz w jaki sposób zostało ono wykonane, możliwe jest odtworzenie funkcji skrótu i uzyskanie prawidłowego zapisu poprzez tzw. atak siłowy (wypróbowanie wszystkich możliwych kombinacji w celu utworzenia tabel korelacji). Funkcje skrótu można podzielić ze względu na wielkości bloku wyjściowego (ilość bitów). Obecne zalecenia amerykańskiej agencji NIST[1] dotyczące stosowania poszczególnych funkcji skrótu mówią, że do nowych aplikacji zalecane są funkcje skrótu z rodziny SHA-2[2], a w przyszłości funkcja SHA-3[3].
- Do niedawna stosowane były funkcje skrótu MD5[4] oraz SHA-1[5], zostały on jednak wycofane ze względu na niewystarczający poziom bezpieczeństwa.
- Tokenizacja – polega na wykorzystaniu jednokierunkowych mechanizmów szyfrujących opartych na przypisaniu identyfikatora (indeksu, sekwencji lub losowo wygenerowanej liczby) w żaden sposób niezwiązanej z pierwotnymi danymi. Technika ta jest często spotykana w sektorze finansowym do autoryzacji operacji bankowych.
Administratorzy danych osobowych przy doborze technik depersonalizacji powinni kierować się wynikiem analizy ryzyka, a także posiłkować się dostępnymi wskazówkami (Grupa Robocza Art. 29, Wytyczne dotyczące oceny skutków dla ochrony danych oraz ustalenia czy przetwarzanie „z dużym prawdopodobieństwem może powodować wysokie ryzyko”) dobrymi praktykami i normami, jak np. norma ISO/IEC 29134:2017 (Information technology – Security techniques – Guidelines for privacy impact assessment). Warto także wykorzystywać dostępne narzędzia informatyczne (np. http://arx.deidentifier.org/) pozwalające na wykonanie anonimizacji za pomocą rożnych technik oraz ocenę ryzyka naruszenia prywatności zanonimizowanego zbioru.
Techniki depersonalizacji danych posiadają zróżnicowany stopień odporności na czynniki ryzyka. Wyróżnia się trzy główne ryzyka zagrażające prywatności:
- Wyodrębnienie: jest to możliwość wyizolowania niektórych lub wszystkich rekordów, które identyfikują daną osobę w zbiorze danych.
- Tworzenie powiązań: jest to możliwość powiązania co najmniej dwóch rekordów dotyczących tego samego podmiotu danych (w tej samej bazie danych lub w dwóch różnych bazach danych).
- Wnioskowanie: pozwala z dużym prawdopodobieństwem wydedukować wartość atrybutu z wartości zbioru innych atrybutów.
Ryzykiem związanym z możliwością naruszenia danych osobowych, jest możliwość identyfikacji osoby, której dane dotyczą, dla zbiorów danych zanonimizowanych – z uwagi na zbyt powierzchowną ich anonimizację lub pseudonimizację.
Ryzyko to związane jest z możliwością dokonania przez użytkowników postronnych identyfikacji danych konkretnej osoby, które w ocenie administratora zostały w pełni zanonimizowane bądź zagregowane. Problem ten dotyczy w szczególności danych statystycznych, które w wyniku zbyt dużej szczegółowości oraz w połączeniu ze zbyt małą próbą (np. dotyczącą jednej instytucji, wspólnoty ludzkiej itp.) cechuje podatność, że osoby wchodzące w skład danej wspólnoty mogą przy pomocy powszechnie znanych im informacji o jej członkach, dokonać odkodowania anonimowych informacji. Ponadto, ryzyko identyfikacji danych może nastąpić także poprzez połączenie zanonimizowanego zbioru danych z innymi zbiorami, co w konsekwencji także pozwala na odkodowanie anonimowych informacji. W efekcie może to prowadzić do naruszenia praw osoby, której dane dotyczą.
[1] National Institute of Standards and Technology
[2] SHA-2 składa się z zestawu czterech funkcji dających skróty wielkości 224, 256, 384 lub 512 bitów
[3] SHA-3 funkcja oparta o Algorytm Keccak charakteryzuje się wyższą wydajnością niż SHA-2 zarówno w implementacjach sprzętowych jak i programowych
[4] MD5 – generuje z ciągu danych o dowolnej długości128-bitowy skrót
[5] SHA-1 tworzą 160-bitowy skrót z wiadomości o maksymalnym rozmiarze 264 bitów i jest oparty na podobnych zasadach co MD5
